Все векторы x in b n имеющие один синдром образуют

Декодирование линейного кода по синдрому
Путь  — матрица размера
— матрица размера  и ранга
и ранга  над полем
над полем 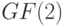 . Эта матрица задает линейное отображение
. Эта матрица задает линейное отображение  пространства
пространства  в пространство
в пространство 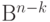 по формуле
по формуле 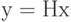 . Ядро этого линейного отображения или множество решений уравнения
. Ядро этого линейного отображения или множество решений уравнения  , образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства
, образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства  на классы равнообразности. В один класс входят все элементы , которые при отображении
на классы равнообразности. В один класс входят все элементы , которые при отображении  переходят в один и тот же элемент пространства
переходят в один и тот же элемент пространства 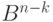 . Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
. Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
Отображение  является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого
является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого  можно найти (построить)
можно найти (построить)  , такой, что
, такой, что  .
.
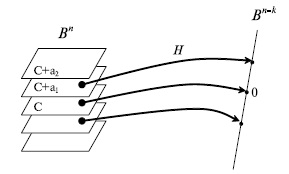
Рис.
7.8.
Разбиение пространства Bn на классы равнообразности
Произведение  называется синдромом [29], [33]. Фактически, синдромом вектора
называется синдромом [29], [33]. Фактически, синдромом вектора 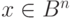 является образ этого вектора при отображении —
является образ этого вектора при отображении — . Все векторы
. Все векторы 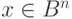 , имеющие один синдром, образуют класс. Так как синдром
, имеющие один синдром, образуют класс. Так как синдром 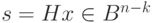 имеет размерность
имеет размерность  , всего существует
, всего существует  классов (если проверочная матрица имеет ранг , в частности, если матрица
классов (если проверочная матрица имеет ранг , в частности, если матрица 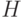 имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом
имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом  . Каждый класс
. Каждый класс 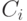 , отличный от кода, порождается «сдвигом»
, отличный от кода, порождается «сдвигом» 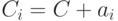 кода на один из векторов
кода на один из векторов 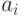 класса . Действительно, если
класса . Действительно, если  ., то есть
., то есть  , тогда
, тогда  и, следовательно,
и, следовательно,  и
и 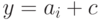 , где
, где 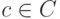 — кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром
— кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром  , можно представить в виде суммы кодового вектора и вектора, имеющего синдром
, можно представить в виде суммы кодового вектора и вектора, имеющего синдром  . Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова
. Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова  , в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор
, в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор 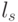 (векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
(векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
Алгоритм декодирования заключается в следующем. Если получен вектор  и
и  , считаем, что ошибкам соответствует наиболее вероятный вектор из класса
, считаем, что ошибкам соответствует наиболее вероятный вектор из класса  , то есть лидер класса . Тогда декодирование осуществляется в вектор
, то есть лидер класса . Тогда декодирование осуществляется в вектор  , получающийся из принятого вектора удалением лидера.
, получающийся из принятого вектора удалением лидера.
Рассмотрим пример построения кода по заданной проверочной матрице и декодирования полученного сообщения по синдрому. Пусть дана проверочная матрица  . Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:
. Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:

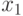 и
и  которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды
которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды  и
и  определяются через и . В итоге все кодовые слова определяются из выражения
определяются через и . В итоге все кодовые слова определяются из выражения
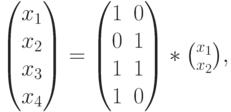
где и  — информационные разряды, а
— информационные разряды, а  — порождающая матрица, столбцами которой являются кодовые векторы.
— порождающая матрица, столбцами которой являются кодовые векторы.
Кодовые слова, рассматриваемые как векторы-столбцы, образуют матрицу кода

Расстояние кода  равно минимальному весу ненулевого слова
равно минимальному весу ненулевого слова 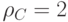 .
.
Найдем смежные классы, которые состоят из векторов пространства  , имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
, имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
Синдромом является любое возможное значение произведения  .
.
В данном случае имеется 4 синдрома:  .Каждому синдрому соответствует смежный класс, синдром соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
.Каждому синдрому соответствует смежный класс, синдром соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
В третьем смежном классе — два потенциальных лидера с весом (нормой), равным 1. Один из них выбирается в качестве лидера произвольно.
Рассмотрим на этом примере процесс декодирования полученного вектора (слова) с использованием синдромов. Пусть передавался кодовый вектор  и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор
и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор 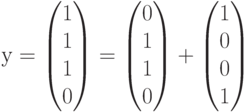 , полученный из переданного вектора в результате добавления вектора ошибки
, полученный из переданного вектора в результате добавления вектора ошибки  (ошибка в первом разряде). Определим синдром, вычислив произведение
(ошибка в первом разряде). Определим синдром, вычислив произведение  . В данном случае получим
. В данном случае получим 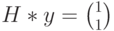 . Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор
. Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор  , соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование
, соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование 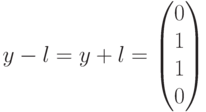 В данном случае декодирование выполнено правильно.
В данном случае декодирование выполнено правильно.
Источник
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 21:59, 14 мая 2016.
Определение
Определение «Определение — Cиндром вектора» |
|---|
Пусть — проверочная матрица: для Пусть — произвольный вектор. — синдром (не зависит от исходного кодового слова). |
Поскольку рассматриваемый код — это нулевое пространство матрицы (т.е. пространство векторов, каждый из которых ортогонален проверочной матрице), то некоторый вектор является кодовым словом тогда и только тогда, когда его синдром равен нулю. Вообще, каждой строке матрицы соответствует проверочное соотношение, которому должны удовлетворять кодовые слова. Компоненты вектора равны нулю для , и не равны нулю для всех остальных.
, где:
— ошибка,
— кодовое слово с ошибкой.
Смежные классы, синдром смежного класса. Лидеры смежного класса
абелева группа, где — подгруппа.
Введем смежный класс по аддитивной подгруппе .
Заметим:
— синдромы совпадают для всех векторов из одного и того же класса смежности.
Теорема Теорема о синдроме смежного класса |
|---|
Два вектора и принадлежат одному и тому же смежному классу тогда и только тогда, когда их синдромы равны. |
Доказательство |
Два элемента группы и принадлежат одному и тому же смежному классу тогда и только тогда, когда есть элемент подгруппы, которой в данном случае является кодовое векторное пространство. Если кодовое пространство — это нулевое пространство матрицы , то вектор принадлежит кодовому пространству тогда и только тогда, когда: Поскольку для умножения матриц справедлив дистрибутивный закон, то Т.о. вектор является кодовым вектором тогда и только тогда, когда синдромы векторов и равны. ч.т.д. |
Синдромов столько же, сколько существует смежных классов:
Декодирование по синдрому. Стандартное расположение линейного кода
Пусть — линейный -код, — нулевой вектор и — остальные кодовые векторы. Тогда таблицу декодирования можно составить следующим образом. Кодовые векторы располагаются в виде строки с нулевым вектором слева. Затем один из оставшихся наборов длины , например , помещается под нулевым вектором. (Обычно это бывает один из наборов, которые наиболее вероятно получить на выходе, если по каналу передавался нулевой вектор.) Далее строка заполняется так, чтобы под каждым кодовым вектором — помещался вектор . Аналогично в первый столбец второй строки помещается вектор и строка заполняется таким же способом. Процесс продолжается до тех пор, пока каждый возможный набор длины не появится где-нибудь в таблице. Это стандартное расположение, конечно, в точности совпадает с таблицей смежных классов. Строки являются смежными классами, а векторы в первом столбце — образующими смежных классов.
Пусть передавался вектор , а получен вектор .
Если , где — — образующий -го смежного класса, то вектор должен находиться в стандартном расположении в -м смежном классе под кодовым словом и и поэтому будет правильно декодирован. Если же вектор не является образующим смежного класса, то вектор должен находиться в некотором смежном классе, например -м, с образующим . Тогда вектор расположен в -й строке, но не под вектором , потому что .
Процесс декодирования может быть значительно упрощен за счет использования таблицы декодирования:
Таблица строится так, что в ней приводятся образующие смежных классов и синдромы для каждого из смежных классов. После того как получен вектор, вычисляется его синдром. Затем по таблице отыскивается образующий смежного класса, являющийся предполагаемым набором ошибок; вычитание его из полученного вектора дает предположительно посланный кодовый вектор. Хотя в большинстве случаев такая процедура во много раз уменьшает требования к объему памяти при осуществлении декодирования, этот объем все-таки может быть очень большим. Например, для двоичного (100,80)-кода требуется таблица декодирования с входами, что конечно, далеко выходит за пределы разумного. Число смежных классов равно — величине, много меньшей, но тем не менее все еще совсем нереальной.
Теорема Утверждение |
|---|
Пусть — линейный двоичный -код (т. е. групповой код), используемый для передачи по двоичному симметричному каналу. Предположим, что все кодовые векторы имеют одну и ту же вероятность быть переданными. Тогда средняя вероятность правильного декодирования совпадает с наибольшей возможной для этого кода, если в качестве таблицы декодирования используется стандартное расположение, в котором каждый образующий смежного класса имеет минимальный вес в своем классе. |
Доказательство |
Обозначим через вектор, стоящий в -й строке и -м столбце таблицы декодирования. Кодовое слово в верхней строке столбца обозначим через ,-. Обозначим через расстояние Хэмминга между полученным вектором и кодовым словом , в которое он преобразуется при декодировании. Тогда вероятность правильного декодирования, если было передано слово , равна где — вероятность ошибки в канале, a . Поскольку имеется кодовых слов, которые предполагаются равновероятными, то при осреднении вероятности правильного декодирования используется весовой множитель : Каждому возможному двоичному вектору на выходе в этой сумме соответствует одно слагаемое, и каждое из этих слагаемых принимает максимальное значение, если соответствующий вектор декодируется в ближайший кодовый вектор в смысле Хэмминга, так как есть монотонно убывающая функция от . Поэтому вероятность правильного декодирования будет максимальной, если каждый полученный вектор будет преобразовываться в ближайший кодовый вектор. Предположим теперь, что некоторый вектор расположен в таблице декодирования под кодовым вектором , так что расстояние Хэмминга между ними равно . Допустим, что ближайший кодовый вектор находится на расстоянии . Пусть — образующий смежного класса, содержащего вектор . Тогда вес вектора равен . Элемент имеет вес и лежит в том же самом смежном классе. Поскольку предполагалось, что имеет минимальный вес в своем смежном классе, то , и поэтому лежит по крайней мере так же близко к , как и к . Число образующих смежных классов веса обозначим через . Вероятность правильного декодирования может быть записана тогда следующим образом: |
Литература
Мак-Вильямс Ф. Дж, Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки: Пер. с англ. — М. : Связь, 1979. — С. 744, ил.
Источник
Декодирование линейного кода по синдрому
Путь  — матрица размера
— матрица размера 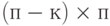 и ранга
и ранга  над полем
над полем 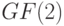 . Эта матрица задает линейное отображение
. Эта матрица задает линейное отображение  пространства
пространства 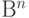 в пространство
в пространство 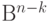 по формуле
по формуле 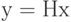 . Ядро этого линейного отображения или множество решений уравнения
. Ядро этого линейного отображения или множество решений уравнения 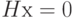 , образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства
, образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства 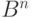 на классы равнообразности. В один класс входят все элементы , которые при отображении
на классы равнообразности. В один класс входят все элементы , которые при отображении  переходят в один и тот же элемент пространства
переходят в один и тот же элемент пространства 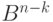 . Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
. Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
Отображение  является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого
является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого  можно найти (построить)
можно найти (построить)  , такой, что
, такой, что 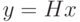 .
.
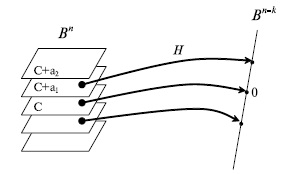
Рис.
7.8.
Разбиение пространства Bn на классы равнообразности
Произведение 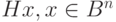 называется синдромом [29], [33]. Фактически, синдромом вектора
называется синдромом [29], [33]. Фактически, синдромом вектора 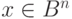 является образ этого вектора при отображении —
является образ этого вектора при отображении —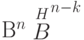 . Все векторы
. Все векторы 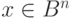 , имеющие один синдром, образуют класс. Так как синдром
, имеющие один синдром, образуют класс. Так как синдром 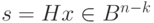 имеет размерность
имеет размерность 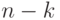 , всего существует
, всего существует  классов (если проверочная матрица имеет ранг , в частности, если матрица
классов (если проверочная матрица имеет ранг , в частности, если матрица 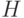 имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом
имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом 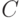 . Каждый класс
. Каждый класс 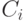 , отличный от кода, порождается «сдвигом»
, отличный от кода, порождается «сдвигом» 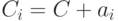 кода на один из векторов
кода на один из векторов  класса . Действительно, если
класса . Действительно, если  ., то есть
., то есть 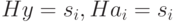 , тогда
, тогда 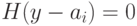 и, следовательно,
и, следовательно,  и
и 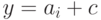 , где
, где 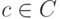 — кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром
— кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром  , можно представить в виде суммы кодового вектора и вектора, имеющего синдром
, можно представить в виде суммы кодового вектора и вектора, имеющего синдром  . Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова
. Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова  , в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор
, в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор 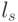 (векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
(векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
Алгоритм декодирования заключается в следующем. Если получен вектор  и
и 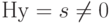 , считаем, что ошибкам соответствует наиболее вероятный вектор из класса
, считаем, что ошибкам соответствует наиболее вероятный вектор из класса 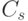 , то есть лидер класса . Тогда декодирование осуществляется в вектор
, то есть лидер класса . Тогда декодирование осуществляется в вектор 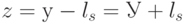 , получающийся из принятого вектора удалением лидера.
, получающийся из принятого вектора удалением лидера.
Рассмотрим пример построения кода по заданной проверочной матрице и декодирования полученного сообщения по синдрому. Пусть дана проверочная матрица 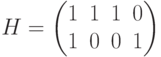 . Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:
. Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:
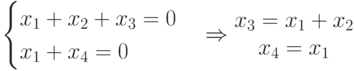
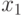 и
и 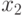 которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды
которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды 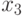 и
и 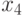 определяются через и . В итоге все кодовые слова определяются из выражения
определяются через и . В итоге все кодовые слова определяются из выражения
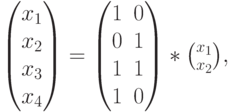
где и 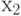 — информационные разряды, а
— информационные разряды, а 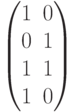 — порождающая матрица, столбцами которой являются кодовые векторы.
— порождающая матрица, столбцами которой являются кодовые векторы.
Кодовые слова, рассматриваемые как векторы-столбцы, образуют матрицу кода
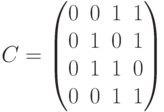
Расстояние кода 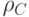 равно минимальному весу ненулевого слова
равно минимальному весу ненулевого слова  .
.
Найдем смежные классы, которые состоят из векторов пространства 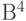 , имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
, имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
Синдромом является любое возможное значение произведения  .
.
В данном случае имеется 4 синдрома: 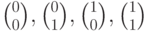 .Каждому синдрому соответствует смежный класс, синдром
.Каждому синдрому соответствует смежный класс, синдром 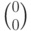 соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
В третьем смежном классе — два потенциальных лидера с весом (нормой), равным 1. Один из них выбирается в качестве лидера произвольно.
Рассмотрим на этом примере процесс декодирования полученного вектора (слова) с использованием синдромов. Пусть передавался кодовый вектор 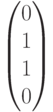 и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор
и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор 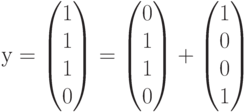 , полученный из переданного вектора в результате добавления вектора ошибки
, полученный из переданного вектора в результате добавления вектора ошибки 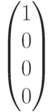 (ошибка в первом разряде). Определим синдром, вычислив произведение
(ошибка в первом разряде). Определим синдром, вычислив произведение  . В данном случае получим
. В данном случае получим 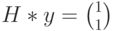 . Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор
. Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор 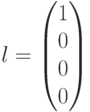 , соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование
, соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование 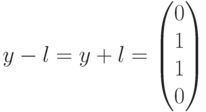 В данном случае декодирование выполнено правильно.
В данном случае декодирование выполнено правильно.
Источник
Декодирование линейного кода по синдрому
Путь — матрица размера и ранга над полем . Эта матрица задает линейное отображение пространства в пространство по формуле . Ядро этого линейного отображения или множество решений уравнения , образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства на классы равнообразности. В один класс входят все элементы , которые при отображении переходят в один и тот же элемент пространства . Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
Отображение является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого можно найти (построить) , такой, что .
Рис.
7.8.
Разбиение пространства Bn на классы равнообразности
Произведение называется синдромом [29], [33]. Фактически, синдромом вектора является образ этого вектора при отображении —. Все векторы , имеющие один синдром, образуют класс. Так как синдром имеет размерность , всего существует классов (если проверочная матрица имеет ранг , в частности, если матрица имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом . Каждый класс , отличный от кода, порождается «сдвигом» кода на один из векторов класса . Действительно, если ., то есть , тогда и, следовательно, и , где — кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром , можно представить в виде суммы кодового вектора и вектора, имеющего синдром . Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова , в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор (векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
Алгоритм декодирования заключается в следующем. Если получен вектор и , считаем, что ошибкам соответствует наиболее вероятный вектор из класса , то есть лидер класса . Тогда декодирование осуществляется в вектор , получающийся из принятого вектора удалением лидера.
Рассмотрим пример построения кода по заданной проверочной матрице и декодирования полученного сообщения по синдрому. Пусть дана проверочная матрица . Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:
и которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды и определяются через и . В итоге все кодовые слова определяются из выражения
где и — информационные разряды, а — порождающая матрица, столбцами которой являются кодовые векторы.
Кодовые с?