Как найти код по синдрому

Слово «синдром» означает обычно совокупность признаков, характерных для того или иного явления. Такой же примерно смысл имеет понятие «синдром» и в теории кодирования. Синдром вектора, содержащего, быть может, ошибки, дает возможность распознать наиболее вероятный характер этих ошибок. Правда, определение, которое мы приводим ниже, не сразу позволяет это увидеть. Синдромом вектора и называется вектор s(u), определяемый равенством:
s(u) = uHT.
Из правила перемножения матриц следует, что синдром есть вектор длины m, где m — число строк проверочной матрицы. В силу определения синдрома вектор u тогда и только тогда является кодовым (u ∈ V) когда его синдром равен нулевому вектору. В самом деле, равенство
uHТ = 0
равносильно тому, что координаты х1, х2, …, хn вектора u удовлетворяют проверочным соотношениям (1) из § 11.
Пусть теперь вектор u не является кодовым, тогда этот вектор обязательно содержит ошибочные символы. Вектор и можно представить тогда в виде суммы посланного кодового вектора υ (который пока не известен) и вектора ошибки е:
u = υ + е. (1)
Ясно, что вектор е = (ε1, ε2, …, εn) содержит ненулевые символы в тех позициях, в которых вектор u содержит искаженные символы.
Важным обстоятельством является то, что синдромы принятого вектора u и вектора ошибки совпадают. Действительно,
s(u) = (υ + е) HT = υHT + еHT = еНТ = s(e). (2)
Рассмотрим теперь множество U всех векторов u’, имеющих тот же синдром, что и вектор u. Пусть а = u’ — u. Тогда
s(a) = (u’ — u)HT = u’HT — uHT = s(u’) — s(u) = 0.
Так как s(a) = 0, то а — кодовый вектор. Обратно, если u’-u — кодовый вектор, то s(u’) = s(u). Таким образом, для интересующего нас множества U имеем:
U = {u + a | a ∈ V}.
На языке теории групп это означает, что U есть смежный класс по подгруппе V (пространство Ln и его кодовое подпространство V можно рассматривать соответственно как группу и ее подгруппу относительно операции сложения векторов).
Сказанное позволяет сделать следующие выводы:
1. Два вектора имеют одинаковый синдром тогда и только тогда, когда они принадлежат одному смежному классу по кодовому подпространству. Таким образом, синдром вектора однозначно определяет тот смежный класс, которому этот вектор принадлежит.
2. Вектор ошибки e для вектора u нужно искать в силу равенства (2) в том же смежном классе, которому принадлежит и сам вектор u.
Разумеется, указание смежного класса, которому принадлежит вектор e, еще не определяет самого этого вектора. Естественно выбрать в качестве в тот вектор смежного класса, для которого вероятность совпадения с е наибольшая. Такой вектор называют лидером смежного класса. Если предположить, что большее число ошибок совершается с меньшей вероятностью, то в качестве лидера следует взять вектор наименьшего веса данного класса и в дальнейшем лидер будет пониматься именно в этом смысле.
При реализации алгоритма декодирования по синдрому составляют таблицу, в которой указываются синдромы si и лидеры ei соответствующих им смежных классов. Алгоритм декодирования заключается тогда в следующем:
1. Вычисляем синдром s(u) принятого вектора u.
2. По синдрому s(u) = si определяем из таблицы лидер ei соответствующего смежного класса.
3. Определяем посланный кодовый вектор υ как разность
υ = u — ei.
Может случиться, что в некоторых смежных классах окажется более одного лидера. Если искаженный вектор u попал в один из таких смежных классов, то разумнее отказаться от исправления ошибки, ограничившись ее обнаружением.
При всей своей простоте и прозрачности алгоритм синдромного декодирования обладает серьезным недостатком. Заключается он в том, что устройство, реализующее этот способ декодирования, должно хранить информацию о лидерах и синдромах. Объем же этой информации может оказаться очень большим даже при умеренных длинах кодовых слов (порядка нескольких десятков). В этом нетрудно убедиться — ведь число лидеров и синдромов совпадает с числом смежных классов, которое по теореме Лагранжа равно qn : qk = qn-k. Так что, например, для двоичного (50, 40)-кода получится 1024 лидеров и столько же синдромов, а для (50,30)-кода число их превзойдет миллион.
Таким образом, мы либо придем к чрезмерному усложнению аппаратуры для синдромного декодирования, либо практически вообще не сможем ее построить. К счастью, имеются коды, декодирование которых не требует обращения к таблице лидеров и синдромов. Простейшие из них — это код Хемминга и его расширенный вариант, рассмотренные в § 9.
Как мы уже знаем, двоичный код Хемминга является линейным, в общем случае имеет длину n = 2m — 1, исправляет одиночные ошибки и обходится минимально возможным для этой цели числом проверок (это число равно m). Таким образом, проверочная матрица кода Хемминга имеет порядок m × (2m — 1). При этом все столбцы этой матрицы должны быть ненулевыми и различными (см. § 11, задача 5). Каждый столбец есть двоичный вектор длины m; всего имеется 2m таких векторов, поэтому для построения проверочной матрицы кода Хемминга длины 2m — 1 нужно выписать (в качестве столбцов этой матрицы) все ненулевые двоичные векторы длины m. Порядок столбцов безразличен, но чаще всего их упорядочивают так, чтобы содержимое каждого столбца являлось двоичной записью его номера (сравни с матрицей (2) из § 11). Вот как выглядит проверочная матрица кода Хемминга длины 15 (m = 4):

Алгоритм исправления одиночных ошибок в этом случае удивительно прост. Если вектор и содержит ошибочный символ в i-й позиции, то синдром s(u) этого вектора совпадает с i-м столбцом проверочной матрицы. Таким образом, этот синдром, читаемый как двоичное число, и есть номер ошибочного символа.
Код Хемминга и в общем случае допускает усовершенствование того же рода, что и (7,4)-код из § 9. Добавление проверочного символа α0, осуществляющего общую проверку на четность, приводит, как и там, к расширенному коду Хемминга с дополнительной способностью обнаруживать Двойные ошибки. Его проверочная матрица легко может быть получена из матрицы кода Хемминга: к каждой строке последней следует впереди приписать нулевой символ, а к получившимся строкам — строку из единиц, соответствующую общей проверке на четность:
α0 + α1 + α2 + … + αn = 0.
Например, из приведенной выше проверочной матрицы для (15,11)-кода Хемминга получается следующая проверочная матрица для расширенного (16,11)-кода:

При вычислении синдрома искаженного вектора возможны две основные ситуации: либо синдром совпадает с одним из столбцов проверочной матрицы, либо это не так. Читатель легко проверит, что первая ситуация соответствует нечетному числу ошибок в слове, а вторая — четному.
В первом случае считаем, что произошла одиночная ошибка, и ее положение определяется номером столбца, с которым совпадает синдром.
Во втором случае считаем, что допущены две или любое большее четное число ошибок, если s(u) ≠ 0. Если же s(u) = 0, то, как обычно, полагаем, что ошибок при передаче не было.
Источник
Декодирование линейного кода по синдрому
Путь  — матрица размера
— матрица размера  и ранга
и ранга  над полем
над полем 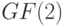 . Эта матрица задает линейное отображение
. Эта матрица задает линейное отображение  пространства
пространства  в пространство
в пространство 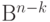 по формуле
по формуле 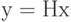 . Ядро этого линейного отображения или множество решений уравнения
. Ядро этого линейного отображения или множество решений уравнения  , образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства
, образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства  на классы равнообразности. В один класс входят все элементы , которые при отображении
на классы равнообразности. В один класс входят все элементы , которые при отображении  переходят в один и тот же элемент пространства
переходят в один и тот же элемент пространства 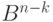 . Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
. Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
Отображение является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого  можно найти (построить)
можно найти (построить)  , такой, что
, такой, что  .
.
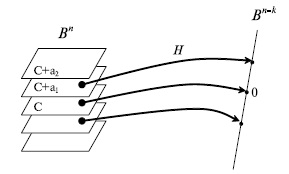
Рис.
7.8.
Разбиение пространства Bn на классы равнообразности
Произведение  называется синдромом [29], [33]. Фактически, синдромом вектора
называется синдромом [29], [33]. Фактически, синдромом вектора  является образ этого вектора при отображении —
является образ этого вектора при отображении — . Все векторы
. Все векторы  , имеющие один синдром, образуют класс. Так как синдром
, имеющие один синдром, образуют класс. Так как синдром  имеет размерность
имеет размерность  , всего существует
, всего существует  классов (если проверочная матрица имеет ранг , в частности, если матрица
классов (если проверочная матрица имеет ранг , в частности, если матрица 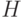 имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом
имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом  . Каждый класс
. Каждый класс 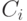 , отличный от кода, порождается «сдвигом»
, отличный от кода, порождается «сдвигом» 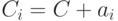 кода на один из векторов
кода на один из векторов 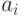 класса . Действительно, если
класса . Действительно, если  ., то есть
., то есть  , тогда
, тогда  и, следовательно,
и, следовательно,  и
и 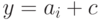 , где
, где 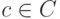 — кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром
— кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром  , можно представить в виде суммы кодового вектора и вектора, имеющего синдром
, можно представить в виде суммы кодового вектора и вектора, имеющего синдром  . Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова
. Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова  , в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор
, в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор 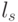 (векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
(векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
Алгоритм декодирования заключается в следующем. Если получен вектор  и
и  , считаем, что ошибкам соответствует наиболее вероятный вектор из класса
, считаем, что ошибкам соответствует наиболее вероятный вектор из класса  , то есть лидер класса . Тогда декодирование осуществляется в вектор
, то есть лидер класса . Тогда декодирование осуществляется в вектор  , получающийся из принятого вектора удалением лидера.
, получающийся из принятого вектора удалением лидера.
Рассмотрим пример построения кода по заданной проверочной матрице и декодирования полученного сообщения по синдрому. Пусть дана проверочная матрица  . Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:
. Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:

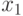 и
и  которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды
которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды  и
и  определяются через и . В итоге все кодовые слова определяются из выражения
определяются через и . В итоге все кодовые слова определяются из выражения
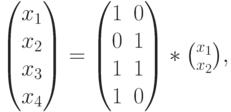
где и  — информационные разряды, а
— информационные разряды, а  — порождающая матрица, столбцами которой являются кодовые векторы.
— порождающая матрица, столбцами которой являются кодовые векторы.
Кодовые слова, рассматриваемые как векторы-столбцы, образуют матрицу кода

Расстояние кода  равно минимальному весу ненулевого слова
равно минимальному весу ненулевого слова 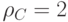 .
.
Найдем смежные классы, которые состоят из векторов пространства  , имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
, имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
Синдромом является любое возможное значение произведения  .
.
В данном случае имеется 4 синдрома:  .Каждому синдрому соответствует смежный класс, синдром
.Каждому синдрому соответствует смежный класс, синдром  соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
В третьем смежном классе — два потенциальных лидера с весом (нормой), равным 1. Один из них выбирается в качестве лидера произвольно.
Рассмотрим на этом примере процесс декодирования полученного вектора (слова) с использованием синдромов. Пусть передавался кодовый вектор  и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор
и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор 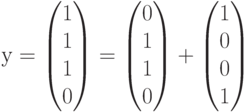 , полученный из переданного вектора в результате добавления вектора ошибки
, полученный из переданного вектора в результате добавления вектора ошибки  (ошибка в первом разряде). Определим синдром, вычислив произведение
(ошибка в первом разряде). Определим синдром, вычислив произведение  . В данном случае получим
. В данном случае получим 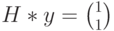 . Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор
. Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор  , соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование
, соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование 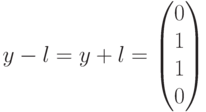 В данном случае декодирование выполнено правильно.
В данном случае декодирование выполнено правильно.
Источник
Код Хэмминга – не цель этой статьи. Я лишь хочу на его примере познакомить вас с самими принципами кодирования. Но здесь не будет строгих определений, математических формулировок и т.д. Эта просто неплохой трамплин для понимания более сложных блочных кодов.
Самый, пожалуй, известный код Хэмминга (7,4). Что значат эти цифры? Вторая – число бит информационного слова — то, что мы хотим передать в целости и сохранности. А первое – размер кодового слова: информация удобренная избыточностью. Кстати термины «информационное слово» и «кодовое слово», употребляются во всех 7-ми книгах по теории помехоустойчивого кодирования, которые мне довелось бегло пролистать.
Такой код исправляет 1 ошибку. И не важно где она возникла. Избыточность несёт в себе 3 бита информации, этого достаточно, чтобы указать на одно из 7 положений ошибки или показать, что её нет. То есть ровно 8 вариантов ответов мы ждём. А 8 = 2^3, вот как всё совпало.
Чтобы получить кодовое слово, нужно информационное слово представить в виде полинома и умножить его на порождающий полином g(x). Любое число, переведя в двоичный вид, можно представить в виде полинома. Это может показаться странным и у не подготовленного читателя сразу встаёт только один вопрос «да зачем же так усложнять?». Уверяю вас, он отпадёт сам собой, когда мы получим первые результаты.
К примеру информационное слово 1010, значение каждого его разряда это коэффициент в полиноме:
Во многих книгах пишут наоборот x+x^3. Не поддавайтесь на провокацию, это вносит только путаницу, ведь в записи числа 2-ичного, 16-ричного, младшие разряды идут справа, и сдвиги мы делаем влево/вправо ориентируясь на это. А теперь давайте умножим этот полином на порождающий полином. Порождающий полином специально для Хэмминга (7,4), встречайте: g(x)=x^3+x+1. Откуда он взялся? Ну пока считайте что он дан человечеству свыше, богами (объясню позже).
Если нужно складывать коэффициенты, то делаем по модулю 2: операция сложения заменяется на логическое исключающее или (XOR), то есть x^4+x^4=0. И в конечном итоге результат перемножения как видите из 4х членов. В двоичном виде это 1001110. Итак, получили кодовое слово, которое будем передавать на сторону по зашумлённому каналу. Замете, что перемножив информационное слово (1010) на порождающий полином (1011) как обычные числа – получим другой результат 1101110. Этого нам не надо, требуется именно «полиномиальное» перемножение. Программная реализация такого умножения очень простая. Нам потребуется 2 операции XOR и 2 сдвига влево (1й из которых на один разряд, второй на два, в соответствии с g(x)=1011):
Давайте теперь специально внесём ошибку в полученное кодовое слово. Например в 3-й разряд. Получиться повреждённое слово: 1000110.
Как расшифровать сообщение и исправить ошибку? Разумеется надо «полиномиально» разделить кодовое слово на g(x). Тут я уже не буду писать иксы. Помните что вычитание по модулю 2 — это то же самое что сложение, что в свою очередь, тоже самое что исключающее или. Поехали:
В программной реализации опять же ничего сверх сложного. Делитель (1011) сдвигаем влево до самого конца на 3 разряда. И начинаем удалять (не без помощи XOR) самые левые единицы в делимом (100110), на его младшие разряды даже не смотрим. Делимое поэтапно уменьшается 100110 -> 0011110 -> 0001000 -> 0000011, когда в 4м и левее разрядах не остаётся единиц, мы останавливаемся.
Нацело разделить не получилось, значит у нас есть ошибка (ну конечно же). Результат деления в таком случае нам без надобности. Остаток от деления является синдром, его размер равен размеру избыточности, поэтому мы дописали там ноль. В данном случае содержание синдрома нам никак не помогает найти местоположение повреждения. А жаль. Но если мы возьмём любое другое информационное слово, к примеру 1100. Точно так же перемножим его на g(x), получим 1110100, внесём ошибку в тот же самый разряд 1111100. Разделим на g(x) и получим в остатке тот же самый синдром 011. И я гарантирую вам, что к такому синдрому мы придём в обще для всех кодовых слов с ошибкой в 3-м разряде. Вывод напрашивается сам собой: можно составить таблицу синдромов для всех 7 ошибок, делая каждую из них специально и считая синдром.
В результате собираем список синдромов, и то на какую болезнь он указывает:
Теперь у нас всё есть. Нашли синдром, исправили ошибку, ещё раз поделили в данном случае 1001110 на 1011 и получили в частном наше долгожданное информационное слово 1010. В остатке после исправления уже будет 000. Таблица синдромов имеет право на жизнь в случае маленьких кодов. Но для кодов, исправляющих несколько ошибок – там список синдромов разрастается как чума. Поэтому рассмотрим метод «вылавливания ошибок» не имея на руках таблицы.
Внимательный читатель заметит, что первые 3 синдрома вполне однозначно указывают на положение ошибки. Это касается только тех синдромов, где одна единица. Кол-во единиц в синдроме называют его «весом». Опять вернёмся к злосчастной ошибке в 3м разряде. Там, как вы помните был синдром 011, его вес 2, нам не повезло. Сделаем финт ушами — циклический сдвиг кодового слова вправо. Остаток от деления 0100011 / 1011 будет равен 100, это «хороший синдром», указывает что ошибка во втором разряде. Но поскольку мы сделали один сдвиг, значит и ошибка сдвинулась на 1. Вот собственно и вся хитрость. Даже в случае жуткого невезения, когда ошибка в 6м разряде, вы, обливаясь потом, после 3 мучительных делений, но всё таки находите ошибку – это победа, лишь потому, что вы не использовали таблицу синдромов.
А как насчёт других кодов Хэмминга? Я бы сказал кодов Хэмминга бесконечное множество: (7,4), (15,11), (31,26),… (2^m-1, 2^m-1-m). Размер избыточности – m. Все они исправляют 1 ошибку, с ростом информационного слова растёт избыточность. Помехоустойчивость слабеет, но в случае слабых помех код весьма экономный. Ну ладно, а как мне найти порождающую функцию например для (15,11)? Резонный вопрос. Есть теорема, гласящая: порождающий многочлен циклического кода g(x) делит (x^n+1) без остатка. Где n – нашем случае размер кодового слова. Кроме того порождающий полином должен быть простым (делиться только на 1 и на самого себя без остатка), а его степень равна размеру избыточности. Можно показать, что для Хэмминга (7,4):
Этот код имеет целых 2 порождающих полинома. Не будет ошибкой использовать любой из них. Для остальных «хэммингов» используйте вот эту таблицу примитивных полиномов:
Соответственно для (15,11) порождающий многочлен g(x)=x^4+x+1. Ну а теперь переходим к десерту – к матрицам. С этого обычно начинают, но мы этим закончим. Для начала преобразую g(x) в матрицу, на которую можно умножить информационное слово, получив кодовое слово. Если g = 1011, то:
Называют её «порождающей матрицей». Дадим обозначение информационному слову d = 1010, а кодовое обозначим k, тогда:
Это довольно изящная формулировка. По быстродействию ещё быстрее, чем перемножение полиномов. Там нужно было делать сдвиги, а тут уже всё сдвинуто. Вектор d указывает нам: какие строки брать в расчёт. Самая нижняя строка матрицы – нулевая, строки нумеруются снизу вверх. Да, да, всё потому что младшие разряды располагаются справа и от этого никуда не деться. Так как d=1010, то я беру 1ю и 3ю строки, произвожу над ними операцию XOR и вуаля. Но это ещё не всё, приготовьтесь удивляться, существует ещё проверочная матрица H. Теперь перемножением вектора на матрицу мы можем получить синдром и никаких делений полиномов делать не надо.
Посмотрите на проверочную матрицу и на список синдромов, который получили выше. Это ответ на вопрос откуда берётся эта матрица. Здесь я как обычно подпортил кодовое слово в 3м разряде, и получил тот самый синдром. Поскольку сама матрица – это и есть список синдромов, то мы тут же находим положение ошибки. Но в кодах, исправляющие несколько ошибок, такой метод не прокатит. Придётся вылавливать ошибки по методу, описанному выше.
Чтобы лучше понять саму природу исправления ошибок, сгенерируем в обще все 16 кодовых слов, ведь информационное слово состоит всего из 4х бит:
Посмотрите внимательно на кодовые слова, все они, отличаются друг от друга хотя бы на 3 бита. К примеру возьмёте слово 1011000, измените в нём любой бит, скажем первый, получиться 1011010. Вы не найдёте более на него похожего слова, чем 1011000. Как видите для формирования кодового слова не обязательно производить вычисления, достаточно иметь эту таблицу в памяти, если она мала. Показанное различие в 3 бита — называется минимальное «хэммингово расстояние», оно является характеристикой блокового кода, по нему судят сколько ошибок можно исправить, а именно (d-1)/2. В более общем виде код Хэмминга можно записать так (7,4,3). Отмечу только, что Хэммингово расстояние не является разностью между размерами кодового и информационного слов. Код Голея (23,12,7) исправляет 3 ошибки. Код (48, 36, 5) использовался в сотовой связи с временным разделением каналов (стандарт IS-54). Для кодов Рида-Соломона применима та же запись, но это уже недвоичные коды.
Список используемой литературы:
1. М. Вернер. Основы кодирования (Мир программирования) — 2004
2. Р. Морелос-Сарагоса. Искусство помехоустойчивого кодирования (Мир связи) — 2006
3. Р. Блейхут. Теория и практика кодов, контролирующих ошибки — 1986
Источник