Декодирование линейных кодов по синдрому

Декодирование линейного кода по синдрому
Путь  — матрица размера
— матрица размера  и ранга
и ранга  над полем
над полем 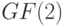 . Эта матрица задает линейное отображение
. Эта матрица задает линейное отображение  пространства
пространства  в пространство
в пространство 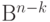 по формуле
по формуле 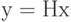 . Ядро этого линейного отображения или множество решений уравнения
. Ядро этого линейного отображения или множество решений уравнения  , образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства
, образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства  на классы равнообразности. В один класс входят все элементы , которые при отображении
на классы равнообразности. В один класс входят все элементы , которые при отображении  переходят в один и тот же элемент пространства
переходят в один и тот же элемент пространства 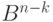 . Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
. Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
Отображение  является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого
является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого  можно найти (построить)
можно найти (построить)  , такой, что
, такой, что  .
.
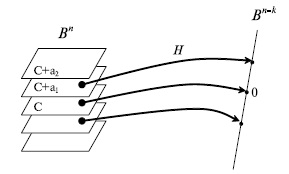
Рис.
7.8.
Разбиение пространства Bn на классы равнообразности
Произведение  называется синдромом [29], [33]. Фактически, синдромом вектора
называется синдромом [29], [33]. Фактически, синдромом вектора  является образ этого вектора при отображении —
является образ этого вектора при отображении — . Все векторы
. Все векторы  , имеющие один синдром, образуют класс. Так как синдром
, имеющие один синдром, образуют класс. Так как синдром  имеет размерность
имеет размерность  , всего существует
, всего существует  классов (если проверочная матрица имеет ранг , в частности, если матрица
классов (если проверочная матрица имеет ранг , в частности, если матрица 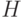 имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом
имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом  . Каждый класс , отличный от кода, порождается «сдвигом»
. Каждый класс , отличный от кода, порождается «сдвигом» 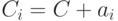 кода на один из векторов
кода на один из векторов 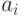 класса . Действительно, если
класса . Действительно, если  ., то есть
., то есть  , тогда
, тогда  и, следовательно,
и, следовательно,  и
и 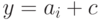 , где
, где 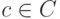 — кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром
— кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром  , можно представить в виде суммы кодового вектора и вектора, имеющего синдром
, можно представить в виде суммы кодового вектора и вектора, имеющего синдром  . Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова
. Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова  , в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор
, в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор  (векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
(векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
Алгоритм декодирования заключается в следующем. Если получен вектор  и
и  , считаем, что ошибкам соответствует наиболее вероятный вектор из класса
, считаем, что ошибкам соответствует наиболее вероятный вектор из класса  , то есть лидер класса . Тогда декодирование осуществляется в вектор
, то есть лидер класса . Тогда декодирование осуществляется в вектор  , получающийся из принятого вектора удалением лидера.
, получающийся из принятого вектора удалением лидера.
Рассмотрим пример построения кода по заданной проверочной матрице и декодирования полученного сообщения по синдрому. Пусть дана проверочная матрица  . Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:
. Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:

 и
и  которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды
которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды  и
и  определяются через и . В итоге все кодовые слова определяются из выражения
определяются через и . В итоге все кодовые слова определяются из выражения
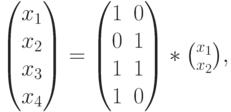
где и  — информационные разряды, а
— информационные разряды, а  — порождающая матрица, столбцами которой являются кодовые векторы.
— порождающая матрица, столбцами которой являются кодовые векторы.
Кодовые слова, рассматриваемые как векторы-столбцы, образуют матрицу кода

Расстояние кода  равно минимальному весу ненулевого слова
равно минимальному весу ненулевого слова 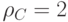 .
.
Найдем смежные классы, которые состоят из векторов пространства 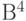 , имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
, имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
Синдромом является любое возможное значение произведения  .
.
В данном случае имеется 4 синдрома:  .Каждому синдрому соответствует смежный класс, синдром
.Каждому синдрому соответствует смежный класс, синдром  соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
В третьем смежном классе — два потенциальных лидера с весом (нормой), равным 1. Один из них выбирается в качестве лидера произвольно.
Рассмотрим на этом примере процесс декодирования полученного вектора (слова) с использованием синдромов. Пусть передавался кодовый вектор  и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор
и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор 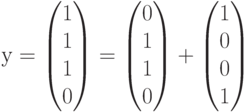 , полученный из переданного вектора в результате добавления вектора ошибки
, полученный из переданного вектора в результате добавления вектора ошибки  (ошибка в первом разряде). Определим синдром, вычислив произведение
(ошибка в первом разряде). Определим синдром, вычислив произведение  . В данном случае получим
. В данном случае получим 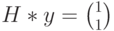 . Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор
. Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор  , соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование
, соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование 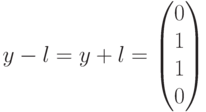 В данном случае декодирование выполнено правильно.
В данном случае декодирование выполнено правильно.
Источник
Слово «синдром» означает обычно совокупность признаков, характерных для того или иного явления. Такой же примерно смысл имеет понятие «синдром» и в теории кодирования. Синдром вектора, содержащего, быть может, ошибки, дает возможность распознать наиболее вероятный характер этих ошибок. Правда, определение, которое мы приводим ниже, не сразу позволяет это увидеть. Синдромом вектора и называется вектор s(u), определяемый равенством:
s(u) = uHT.
Из правила перемножения матриц следует, что синдром есть вектор длины m, где m — число строк проверочной матрицы. В силу определения синдрома вектор u тогда и только тогда является кодовым (u ∈ V) когда его синдром равен нулевому вектору. В самом деле, равенство
uHТ = 0
равносильно тому, что координаты х1, х2, …, хn вектора u удовлетворяют проверочным соотношениям (1) из § 11.
Пусть теперь вектор u не является кодовым, тогда этот вектор обязательно содержит ошибочные символы. Вектор и можно представить тогда в виде суммы посланного кодового вектора υ (который пока не известен) и вектора ошибки е:
u = υ + е. (1)
Ясно, что вектор е = (ε1, ε2, …, εn) содержит ненулевые символы в тех позициях, в которых вектор u содержит искаженные символы.
Важным обстоятельством является то, что синдромы принятого вектора u и вектора ошибки совпадают. Действительно,
s(u) = (υ + е) HT = υHT + еHT = еНТ = s(e). (2)
Рассмотрим теперь множество U всех векторов u’, имеющих тот же синдром, что и вектор u. Пусть а = u’ — u. Тогда
s(a) = (u’ — u)HT = u’HT — uHT = s(u’) — s(u) = 0.
Так как s(a) = 0, то а — кодовый вектор. Обратно, если u’-u — кодовый вектор, то s(u’) = s(u). Таким образом, для интересующего нас множества U имеем:
U = {u + a | a ∈ V}.
На языке теории групп это означает, что U есть смежный класс по подгруппе V (пространство Ln и его кодовое подпространство V можно рассматривать соответственно как группу и ее подгруппу относительно операции сложения векторов).
Сказанное позволяет сделать следующие выводы:
1. Два вектора имеют одинаковый синдром тогда и только тогда, когда они принадлежат одному смежному классу по кодовому подпространству. Таким образом, синдром вектора однозначно определяет тот смежный класс, которому этот вектор принадлежит.
2. Вектор ошибки e для вектора u нужно искать в силу равенства (2) в том же смежном классе, которому принадлежит и сам вектор u.
Разумеется, указание смежного класса, которому принадлежит вектор e, еще не определяет самого этого вектора. Естественно выбрать в качестве в тот вектор смежного класса, для которого вероятность совпадения с е наибольшая. Такой вектор называют лидером смежного класса. Если предположить, что большее число ошибок совершается с меньшей вероятностью, то в качестве лидера следует взять вектор наименьшего веса данного класса и в дальнейшем лидер будет пониматься именно в этом смысле.
При реализации алгоритма декодирования по синдрому составляют таблицу, в которой указываются синдромы si и лидеры ei соответствующих им смежных классов. Алгоритм декодирования заключается тогда в следующем:
1. Вычисляем синдром s(u) принятого вектора u.
2. По синдрому s(u) = si определяем из таблицы лидер ei соответствующего смежного класса.
3. Определяем посланный кодовый вектор υ как разность
υ = u — ei.
Может случиться, что в некоторых смежных классах окажется более одного лидера. Если искаженный вектор u попал в один из таких смежных классов, то разумнее отказаться от исправления ошибки, ограничившись ее обнаружением.
При всей своей простоте и прозрачности алгоритм синдромного декодирования обладает серьезным недостатком. Заключается он в том, что устройство, реализующее этот способ декодирования, должно хранить информацию о лидерах и синдромах. Объем же этой информации может оказаться очень большим даже при умеренных длинах кодовых слов (порядка нескольких десятков). В этом нетрудно убедиться — ведь число лидеров и синдромов совпадает с числом смежных классов, которое по теореме Лагранжа равно qn : qk = qn-k. Так что, например, для двоичного (50, 40)-кода получится 1024 лидеров и столько же синдромов, а для (50,30)-кода число их превзойдет миллион.
Таким образом, мы либо придем к чрезмерному усложнению аппаратуры для синдромного декодирования, либо практически вообще не сможем ее построить. К счастью, имеются коды, декодирование которых не требует обращения к таблице лидеров и синдромов. Простейшие из них — это код Хемминга и его расширенный вариант, рассмотренные в § 9.
Как мы уже знаем, двоичный код Хемминга является линейным, в общем случае имеет длину n = 2m — 1, исправляет одиночные ошибки и обходится минимально возможным для этой цели числом проверок (это число равно m). Таким образом, проверочная матрица кода Хемминга имеет порядок m × (2m — 1). При этом все столбцы этой матрицы должны быть ненулевыми и различными (см. § 11, задача 5). Каждый столбец есть двоичный вектор длины m; всего имеется 2m таких векторов, поэтому для построения проверочной матрицы кода Хемминга длины 2m — 1 нужно выписать (в качестве столбцов этой матрицы) все ненулевые двоичные векторы длины m. Порядок столбцов безразличен, но чаще всего их упорядочивают так, чтобы содержимое каждого столбца являлось двоичной записью его номера (сравни с матрицей (2) из § 11). Вот как выглядит проверочная матрица кода Хемминга длины 15 (m = 4):

Алгоритм исправления одиночных ошибок в этом случае удивительно прост. Если вектор и содержит ошибочный символ в i-й позиции, то синдром s(u) этого вектора совпадает с i-м столбцом проверочной матрицы. Таким образом, этот синдром, читаемый как двоичное число, и есть номер ошибочного символа.
Код Хемминга и в общем случае допускает усовершенствование того же рода, что и (7,4)-код из § 9. Добавление проверочного символа α0, осуществляющего общую проверку на четность, приводит, как и там, к расширенному коду Хемминга с дополнительной способностью обнаруживать Двойные ошибки. Его проверочная матрица легко может быть получена из матрицы кода Хемминга: к каждой строке последней следует впереди приписать нулевой символ, а к получившимся строкам — строку из единиц, соответствующую общей проверке на четность:
α0 + α1 + α2 + … + αn = 0.
Например, из приведенной выше проверочной матрицы для (15,11)-кода Хемминга получается следующая проверочная матрица для расширенного (16,11)-кода:

При вычислении синдрома искаженного вектора возможны две основные ситуации: либо синдром совпадает с одним из столбцов проверочной матрицы, либо это не так. Читатель легко проверит, что первая ситуация соответствует нечетному числу ошибок в слове, а вторая — четному.
В первом случае считаем, что произошла одиночная ошибка, и ее положение определяется номером столбца, с которым совпадает синдром.
Во втором случае считаем, что допущены две или любое большее четное число ошибок, если s(u) ≠ 0. Если же s(u) = 0, то, как обычно, полагаем, что ошибок при передаче не было.
Источник
Существует три основных метода декодирования линейных кодов:
— декодирование по максимуму правдоподобия (по минимуму расстояния);
— мажоритарное декодирование (по большинству проверок);
— декодирование по синдрому.
Декодирование по максимуму правдоподобия
Правило декодирования:
В качестве переданного слова следует выбирать слово, которое ближе всего по Хэммингу к принятому .
Рисунок 5.1 – Структурная схема декодера по минимуму расстояния.
На рисунке: УСр – устройство сравнения; ГКС – генератор кодовых слов; РУ – решающее устройство.
Данный метод используется, когда число информационных символов мало ( ).
Мажоритарное декодирование
Основано на том, что каждый информационный символ можно выразить через другие символы кодового слова с помощью линейных соотношений. Окончательное решение о значении символа принимается по мажоритарному принципу (по большинству) результатов таких проверок.
Существует три способа построения систем проверочных уравнений для декодирования символа:
— системы с разделенными проверками – символ, относительно которого разделяется система, входит во все уравнения. Любой другой символ входит не более, чем в одно уравнение. Для коррекции ошибок необходимо уравнений в системе;
— системы с -связанными проверками – символ, относительно которого разрешается система, входит во все уравнения. Любой другой символ входит не более, чем в уравнений. Для коррекции ошибок необходимо уравнений в системе;
— системы с квазиразделенными проверками – система разделима относительно некоторой суммы символов. На первом этапе она разрешается относительно суммы символов, а на втором – относительно конкретного символа.
Рисунок 5.2 – Структурная схема мажоритарного декодера.
На рисунке: 1…k – устройства, реализующие проверки для соответствующей системы; МЭ – мажоритарный элемент, принимающий решение о значении символа по большинству результатов проверок.
Пример 5.1:
Код (8,4) задан матрицей:
.
Система уравнений по матрице Н:
Система проверочных уравнений для :
Система проверочных уравнений для :
Система проверочных уравнений для :
Система проверочных уравнений для :
Пусть .
Результат декодирования: .
Декодирование по синдрому
Основано на стандартной таблице – таблице всех возможных принятых из канала слов, организованной таким образом, что может быть найдено ближайшее к принятому кодовое слово. Она содержит строк и столбцов.
Таблица – Стандартная таблица.
| s1=(0…0) r | b1=(0…0) n | b2 | … | bM |
| s2… sN | e2… eN | b2+e2… b2+eN | … … … | bM+e2… bM+eN |
bi – кодовые слова;
ej – векторы ошибок – образцы ошибок минимального веса;
bi+ej – слова, не являющиеся кодовыми;
si=ei∙HT – синдромы – векторы размерностью r, указывающие на наличие и расположение ошибок в принятом слове.
Правило декодирования:
1. Вычисляется синдром по принятому слову :
.
Если , то является кодовым словом. В противном случае ( ) содержит ошибки.
2. По находится наиболее правдоподобный вектор ошибки .
3. Ближайшее к принятому кодовое слово получается в результате суммирования и :
.
Рисунок 5.3 – Структурная схема декодера по синдрому.
На рисунке: Б – буфер хранения принятого слова; БВС – блок вычисления синдрома; С – селектор (дешифратор) синдрома; К – корректор.
Данный метод используется, когда число проверочных символов мало (<10).
Пример:
Составить стандартную таблицу для систематического кода (5,2) с порождающей матрицей:
.
Таблица должна содержать строк и столбцов.
Таблица – Стандартная таблица.
| b1=(00000) | b2=(01011) | b3=(10101) | b4=(11110) | s1=(000) |
| e2=(00001) | b2+e2=(01010) | b3+e2=(10100) | b4+e2=(11111) | s2=e2∙HT=(001) |
| e3=(00010) | b2+e3=(01001) | b3+e3=(10111) | b4+e2=(11100) | s3=e3∙HT=(010) |
| e4=(00100) | b2+e4=(01111) | b3+e4=(10001) | b4+e2=(11010) | s4=e4∙HT=(100) |
| e5=(01000) | b2+e5=(00011) | b3+e5=(11101) | b4+e2=(10110) | s5=e5∙HT=(011) |
| e6=(10000) | b2+e6=(11011) | b3+e6=(00101) | b4+e2=(01110) | s6=e6∙HT=(101) |
| e7=(01100) | b2+e7=(00111) | b3+e7=(11001) | b4+e2=(10010) | s7=e7∙HT=(111) |
| e8=(11000) | b2+e8=(10011) | b3+e8=(01101) | b4+e2=(00110) | s8=e8∙HT=(110) |
Пусть (10111). Проведем декодирование.
1. ;
2. ;
3. .
ДОМАШНЕЕ ЗАДАНИЕ:
1. [3.1.2] с. 309…312, 317…318;
[3.1.3] с. 205…208;
[3.1.5] с. 147.. 149, 150…151;
[3.1.14] с. 258…261, 271…273.
2. Код (7,4) задан порождающей матрицей:
.
Провести декодирование по синдрому принятого слова .
6 НЕПРЕРЫВНЫЕ (РЕКУРРЕНТНЫЕ) КОДЫ
Общие сведения
Непрерывные коды используют непрерывную обработку информации короткими фрагментами. Кодер для непрерывного кода обладает памятью, т.е. символы на его выходе зависят не только от очередного фрагмента информационных символов на входе, но и предыдущих символов на его входе и (или) выходе. Поэтому коды называются рекуррентными (recur – возвращаться, повторяться).
Эти коды применяют для обнаружения и исправления пакетов ошибок. Пакет ошибок – ошибка, затрагивающая цепочку символов. Описывается длиной и вектором ошибок .
Пример 6.1:
Пакеты ошибок длиной 4 могут быть такими:
К непрерывным кодам относят цепной и сверточные. Цепной код является простейшим случаем сверточных.
Цепной код
В таком коде после каждого информационного символа следует проверочный. Закодированная последовательность имеет вид:
где — шаг сложения. Определяет корректирующие возможности кода;
— информационные символы;
— проверочные символы. Формируются по правилу:
Код позволяет исправить пачки ошибок длиной , если они разделены защитным интервалом .
Сверточные коды (ск)
Это линейные, рекуррентные коды. Название обусловлено тем, что кодирование информации СК представляет собой операцию свертки двух функций:
где — входная последовательность информационных символов;
— номер входа;
— выходная последовательность кодовых символов;
— номер выхода;
— порождающий полином.
Набор порождающих полиномов определяет внутреннюю конструкцию кодера.
Рисунок 6.1 – Обобщенная структурная схема кодера СК.
Кодирующее устройство содержит регистров сдвига и сумматоры по модулю два. Количество двоичных разрядов -ого регистра сдвига определяется старшей степенью полинома . Коэффициенты полинома определяют связи между двоичными разрядами -ого регистра сдвига и -ым выходом кодера.
На практике чаще используются коды с единственным входным потоком ( ) поэтому индекс обычно опускается.
Пример 6.2:
Рисунок 6.2 – Структурная схема кодера несистематического СК с и .
Источник
Путь — матрица размера и ранга над полем . Эта матрица задает линейное отображение пространства в пространство по формуле . Ядро этого линейного отображения или множество решений уравнения , образующее подпространство пространства , является линейным кодом. Можно рассмотреть разбиение пространства на классы равнообразности. В один класс входят все элементы , которые при отображении переходят в один и тот же элемент пространства . Элемент пространства , в который переходят все элементы одного класса, называется синдромом. Pис.7.8 иллюстрирует разбиение пространства на классы равнообразности.
Отображение является отображением на все пространство . Для систематической матрицы H это практически очевидно. Действительно, для любого можно найти (построить) , такой, что .
Рис. 7.8.Разбиение пространства Bn на классы равнообразности
Произведение называется синдромом [29], [33]. Фактически, синдромом вектора является образ этого вектора при отображении -. Все векторы , имеющие один синдром, образуют класс. Так как синдром имеет размерность , всего существует классов (если проверочная матрица имеет ранг , в частности, если матрица имеет систематический вид). Из определения линейного кода следует, что класс, которому соответствует нулевой синдром, является кодом . Каждый класс , отличный от кода, порождается «сдвигом» кода на один из векторов класса . Действительно, если ., то есть , тогда и, следовательно, и , где — кодовое слово. Таким образом, любой некодовый вектор, имеющий синдром , можно представить в виде суммы кодового вектора и вектора, имеющего синдром . Представление такого вида не является единственным. Некодовый вектор в этой сумме можно рассматривать как вектор ошибок, произошедших в тех разрядах кодового слова , в которых соответствующие компоненты вектора равны 1. Из всех векторов ошибок, имеющих один синдром, наиболее вероятным является вектор (векторы) с минимальным весом (числом единичных компонент). Такой вектор (векторы) называется лидером класса.
Алгоритм декодирования заключается в следующем. Если получен вектор и , считаем, что ошибкам соответствует наиболее вероятный вектор из класса , то есть лидер класса . Тогда декодирование осуществляется в вектор , получающийся из принятого вектора удалением лидера.
Рассмотрим пример построения кода по заданной проверочной матрице и декодирования полученного сообщения по синдрому. Пусть дана проверочная матрица . Запишем уравнение для определения кодовых векторов (слов) для данной матрицы:
и которые можно рассматривать как информационные разряды, задаются произвольно (всего 4 варианта 00, 01, 10, 11), а проверочные разряды и определяются через и . В итоге все кодовые слова определяются из выражения
где и — информационные разряды, а — порождающая матрица, столбцами которой являются кодовые векторы.
Кодовые слова, рассматриваемые как векторы-столбцы, образуют матрицу кода
Расстояние кода равно минимальному весу ненулевого слова .
Найдем смежные классы, которые состоят из векторов пространства , имеющих одинаковый синдром, и выберем в каждом классе лидера (вектор из класса с минимальным весом).
Синдромом является любое возможное значение произведения .
В данном случае имеется 4 синдрома: .Каждому синдрому соответствует смежный класс, синдром соответствует коду. Смежные классы (столбцы матриц) для каждого синдрома и выбранные лидеры приведены в таблице.
В третьем смежном классе — два потенциальных лидера с весом (нормой), равным 1. Один из них выбирается в качестве лидера произвольно.
Рассмотрим на этом примере процесс декодирования полученного вектора (слова) с использованием синдромов. Пусть передавался кодовый вектор и в процессе переачи произошла ошибка в первом разряде. Это означает, что на приемном конце был получен вектор , полученный из переданного вектора в результате добавления вектора ошибки (ошибка в первом разряде). Определим синдром, вычислив произведение . В данном случае получим . Это означает, что полученный вектор водит в четвертый смежный класс (см. таблицу). Лидером этого смежного класса является вектор , соответствующий данному синдрому. Вычитая (добавляя) лидер к принятому вектору, производим декодирование В данном случае декодирование выполнено правильно.
Лекция 8
Процессам обработки, в том числе и обработке данных, присуще свойство, заключающееся в том, что обработка состоит из нескольких стадий, этапов, операций, которые могут рассматриваться как более простые процессы (подпроцессы) обработки. Стадии обработки могут быть взаимосвязаны. Выполнение тех или иных этапов обработки зависит от результатов выполнения других этапов.
Описание процессов обработки осуществляется в виде совокупности предписаний или достаточно простых действий, которые должны быть выполнены для придания объекту обработки желаемых свойств. Подобные описания, представленные в формализованном виде, обычно называются алгоритмами.
Для исследования процессов обработки данных используются различные формальные модели: конечные автоматы, сети Петри, взаимодействующие последовательные процессы Хоара, системы и сети массового обслуживания и многие другие. Они описывают различные аспекты процессов обработки. Некоторые из этих моделей рассматриваются далее.
Источник